|
I would say that one of the most basic and heavily used applications on an iPhone is the standard Mail app that comes as default on every iOS installation. But I realised recently that in all my years examining these devices, I'd relied on the forensics software to parse the emails for me and had never taken a good look at how iOS actually stored email messages. This came about mainly while I was implementing Email as a node in Artex (and in my next big project that I'm not supposed to talk about yet).
We will start by looking at the Mail folder located at /private/var/mobile/Library/Mail
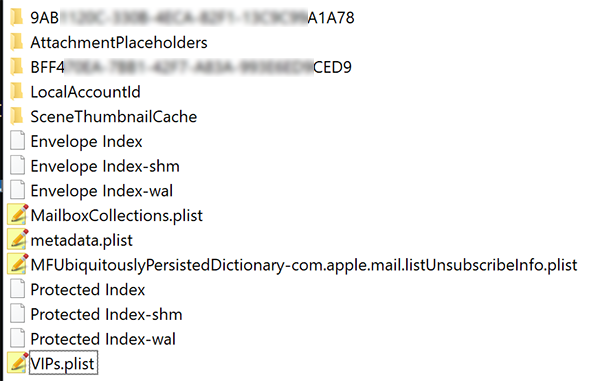
Although not every Mail folder will look like this, it's fairly typical and shows everything I want to talk about.
Of important note are the folders that I have partially blurred, Envelope Index, Protected Index.
| Object |
Description |
| Blurred Folder/s |
There is one of these folders for each of the Accounts configured on the device. The folders contain the Inbox, Sent, Draft folders.etc. |
| Envelope Index |
A database (and corresponding shm and wal files) which contains numerous tables related to the mailboxes of each account. I think of this as like MetaData for the emails. |
| Protected Index |
A database (and corresponding shm and wal files) which contains very few tables but much more evidential data including actual message content in some cases. |
The more I dive into the inner workings of the default Apple apps, the more it strikes me just how different they all function. Even with basic things such as naming conventions they are massively different.
For example, you have photos.sqlite for photos, sms.db for messages, CallHistory.storedata for calls and AddressBook.sqlitedb for contacts, to name just a few. Multiple different extensions for what are all SQLite databases. Then you have primary keys being called either <descriptor>_id, Z_PK or ROWID.
...What I'm getting at is that Apple appears to have very little consistency in the background of their apps. And I was not surprised to find that Mail is no exception. To make it a little more "unique" though, the relationships between the data span not only between tables, but between files.
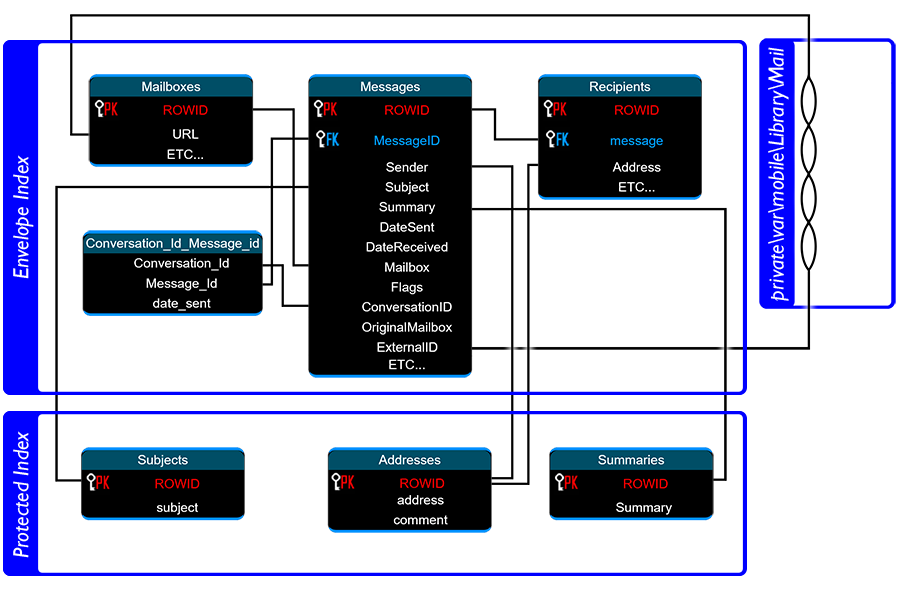
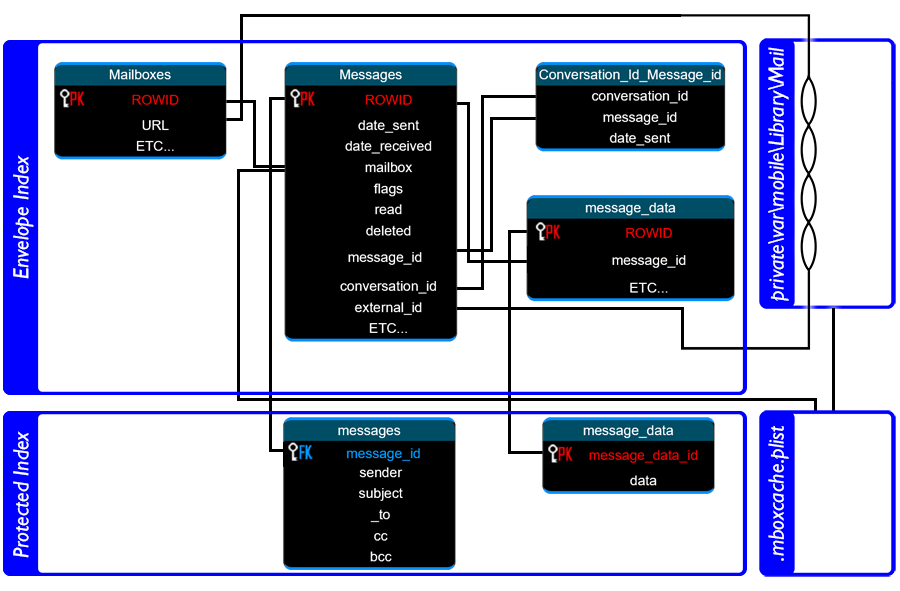
The Envelope Index and Protected Index databases are relational. The .mboxCache.plist file may also be required to access data that could for all intents and purposes be saved within the database too I'm sure... but... Apple i guess...?
Anyway, on to the databases' themselves.
When I started investigating iOS Mail, I was working on an iOS12 device. But prior to finishing it, I had reason to look at iOS13 and found a few differences. No doubt iOS11 is different again. This article will only cover iOS12 and iOS13.
I think of this database as being kind of like reading a literal envelope and am fairly sure that's how it got its name.
Information stored in this database includes high level information (such as could be worked out from reading an envelope). Things like the date the message was sent, Thread/Message ID's and the mailbox (Inbox, Sent, Draft etc) but it doesn't include any of the really useful stuff like who it is to/from or the actual content. That hopefully comes later.
If Envelope Index is like reading the sealed envelope, then Protected Index is like the envelope contents. It contains the important data such as the email addresses of the sender/recipients and message summary. Sometimes it even appears to contain the full message.
Any full message that's not within this database is most likely saved as an emlx file, which we'll come onto shortly.
Protected Index in iOS13 consists of 3 useful tables; Addresses, Subjects and Summaries and they contain exactly what you think they would.
Addresses is literally a list of email Addresses and "Comments" which appear to be be equivalent of the Full Name.
Subjects is literally a list of the email Subjects.
Summaries is a list of the first 500 bytes of the email content. Basically what you see on the Inbox screen.
There is also a table called protected_message_data but on the devices I have looked at it has always been empty.
Protected Inbox in iOS12 consists of just 2 useful tables; messages and message_data.
message_data contains the first 500 bytes of each message.
messages contains the sender, the subject and the to, cc and bcc addresses.
Next we will look at the Account folders within the main Mail directory.
Typically this directory will contain a folder for each of the mailboxes within the account. So Inbox, Sent, Deleted, Draft etc..
The URL field within the Envelope > Mailboxes table contains the reference to the Mailbox folder.
It may simply be listed as "account / mailboxname". eg : "imap://abcdefg/Inbox" or "imap://abcdefg/Trash" but there may also be times where the url ends with a number instead of the expected mailbox name. That's where the .mailboxCache.plist file comes in (again, this is not always the case and your mboxcache may appear different).
Under the mboxes node, you will find numerous mailboxes that each have both a MailboxName and a DAFolderID field. This DAFolderID is what is referenced in the url field in the database.
 |
You can see how item 4 has the DAFolderID of 8 and the name of "Drafts".
Therefore in the database, if the URL ends with 8, it simply requires substituting for the work "Drafts".
Likewise:
9 = important mail
12 = Junk
13 = Junk Email
*These are examples only; the ID number/Name combination may be different on your device. |
So if my Mailbox URL was imap://abcdef/9 I would use the mboxCache file to resolve the 9 to "important mail".
Knowing this is important because also within the account / mailbox folders, you will find the actual email messages stored as emlx and partial emlx files.

At first glance, it's easy enough to simply rename the .emlx file as a .HTML file and open it in a browser. In some cases, this will probably be enough to get the gist of what the file contains but you will likely notice that there is a lot of information missing.
You could simply concatenate the two (or more) partial files and rename that as a HTML. This will at least give you all the data. Although to see what the gist of the message is but there will also be some characters that aren't displayed correctly.

This is an example of an emlx file that has simply been renamed to HTML and opened in a browser. It's a rather extreme example of how bad this approach could be.
The poor formatting is because the email content is encoded using quoted-printable (QP) encoding (More information here) which uses the equal symbol as an escape character. Because we are viewing the data as HTML, the browser is not expecting the equal sign to be an escape character and is therefore interpreting the following letters incorrectly, showing them as if they are part of the message.

You can see in the header that the encoding method is defined as Quoted Printable.
The string "=0D" that you can see littered throughout the email is the QP represenation of a new line.
The string "=3D" is the equals sign itself, which is heavily used in HTML code. For example when specifying the alignment of text, the browser expects somthing like align="left", but because of the QP encoding, it actually gets align=3D"left" which it cannot understand.
For anyone unfamiliar with the term "Escape Character", it is basically a way to tell the computer that the following data needs interpreting differently.
A simple example would be within a text file where ordinarily, the letter 'n' is printed like any other. But if it is is preceded with the escape character '\' (so you you have '\n'), then that instructs the computer to add a a new line instead of printing the letter.
Likewise, '\t' adds a tab, and '\r' adds a carriage return. There are lots of uses for escape characters, and different escape characters depending on the environment you are in. |
There are plenty of tools and scripts available online (such as https://www.webatic.com/quoted-printable-convertor) for decoding QP. And if you were to open the file above in a text editor such as Notepad++, the contents can be copied out and pasted into the website given. The resulted decoded text can be placed back into a HTML file and reopened which results in:
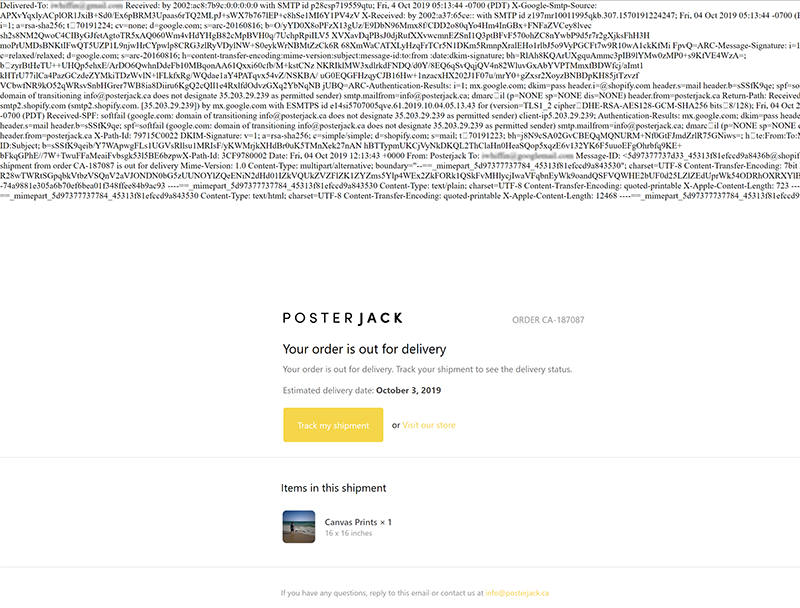
This decoded text still maintains the header information but now is a nicely formatted HTML based email.
Alternately, only the header may display correctly and everything else is gibberish. This is likely as the message body is encoded in Base64.

An example of a Base64 encoded email. The header information can still be read but the message content cannot.
In this case, you need to take all of the Base64 content and decode it. Again, plenty of online decoders exist (https://www.base64decode.org/) and the c# code to do it is really rather simple.
string originalB64String = <THIS IS THE BASE64 STRING>
var base64EncodedBytes = System.Convert.FromBase64String(originalB64String);
string plainText = System.Text.Encoding.UTF8.GetString(base64EncodedBytes); |
Once the base64 is decoded, it may be either plain text or HTML code, either way its pretty easy to deal with.
Attachments, such as images, may also be encoded in Base64 and require decoding in similar fashion. Obviously though, you wouldn't be converting the base64 image to a string.
Thank you for reading! Hopefully you have found some of this information useful. I always find it interesting looking into aspects of a device that you think you already understand and finding out new things.
I don't know whether it was the fact that emails were unavailable for so long, that I can't actually think of a case I've worked where iOS emails have been that useful or the fact that the forensics tools performed all the required magic, but I went for a long time without fully appreciating how iOS actually stores emails or the methods required to access and verify them.
Remember, you can download my iOS Usage Visualization tool "ArtEx" for FREE from the Software section. Email is partially supported; I am aware it needs more work relating to Flags and Attachments and I hope to get that done relatively soon.
|